인문 사회과학 연구를 수행하는 자강헌의 접근은 "인간사고의 유일한 도구는 언어다."라는 전제가 있습니다.
Jagangheon's approach to humanistic research begins with one premise: "Language is the only tool of human thought."
그리고 인공지능이 오래전부터 활용되었지만 세계인의 주목을 받았던 챗GPT 역시 대규모언어모델(LLM)로 출발했고, 이후 그래픽이나 동영상분야의 활용성을 높여 갔습니다.
AI has been used for a long time, but ChatGPT, which captured the world's attention, also started from a Large Language Model (LLM) and has since expanded into graphics and video.
그런데 중국의 모델인 Deep Seek의 출연으로 인공지능 생태계가 지각변동적 충격을 받았고, 계속해서 중국은 가성비를 표방하는 인해전술을 구사하고 있습니다.
Then DeepSeek from China sent tectonic shockwaves through the AI ecosystem, and China continues to deploy human-wave tactics emphasizing cost-effectiveness.
토큰 최대화(tokenmaxxing)
Tokenmaxxing
인공지능을 말하면서 Token이라는 단어를 멀리 할 수 없습니다.
When talking about AI, we cannot avoid the word "token."
뉴욕 타임스가 지난달에 보도한 것처럼 인공지능 생태계는 "토큰 최대화(tokenmaxxing)"를 하고 있습니다.
As the New York Times reported last month, the AI ecosystem is engaged in "tokenmaxxing."
뉴욕 타임스는 "오픈AI의 한 엔지니어가 2,100억 개의 '토큰'을 처리했는데, 이는 위키피디아를 33번 채울 수 있는 양"이라고 보도했습니다.
The NYT reported that "one OpenAI engineer processed 210 billion tokens — enough to fill Wikipedia 33 times."
그리고 엔비디아 CEO 젠슨 황은 팟캐스트에서 연봉 50만 달러를 받는 엔지니어가 토큰 구매에 연간 25만 달러 미만을 지출한다면 "매우 우려스럽다"고 말했습니다. 엔비디아가 엔지니어링 팀을 위해 20억 달러를 토큰 구매에 투자하고 있는지 묻는 질문에 그는 "노력하고 있다"고 답했습니다.
Nvidia CEO Jensen Huang said on a podcast that if an engineer earning $500K spends less than $250K on token purchases annually, he would be "very concerned." Asked whether Nvidia invests $2 billion in token purchases for its engineering teams, he replied, "We're trying."
또 작년에는 오픈AI가 API를 통해 대량의 데이터를 처리한 개발자와 조직을 실버, 블랙, 블루의 세등급으로 나누어 토큰 사용권을 부여하는 프로그램을 도입했습니다.
Last year, OpenAI introduced a program dividing developers and organizations into Silver, Black, and Blue tiers based on API data volume, granting token usage rights accordingly.
지능시대에서 토큰은 인지 노동의 단위이다
In the Intelligence Age, Tokens Are Units of Cognitive Labor
토큰 사용량은 누가 봐도 새로운 지위의 상징이 되었습니다. 최고 연구소의 엔지니어들은 마치 실력 없는 프로그래머가 코드 줄 수를 자랑하듯 토큰 사용량을 과시합니다.
Token usage has clearly become a new status symbol. Engineers at top labs flaunt their token consumption like mediocre programmers boasting about lines of code.
일부 엔지니어는 급여보다 토큰 구매에 더 많은 돈을 쓰고 있습니다. 토큰 예산은 급여, 주식, 보너스와 함께 보상의 "네 번째 요소"로 제시되고 있습니다. 구직자들은 면접에서 "채용 시 토큰이 얼마나 지급되나요?"라고 묻습니다. 이제 API 비용이 인건비 예산과 경쟁하고 있습니다.
Some engineers spend more on token purchases than their salary. Token budgets are being presented as the "fourth pillar" of compensation alongside salary, equity, and bonuses. Job candidates ask in interviews, "How many tokens come with the offer?" API costs now compete with payroll budgets.
젠슨 황은 "토큰 한도를 소진하지 않는다면 CAD 도구를 사용하지 않고 연필로 직접 설계하는 칩 설계자와 같다"고 말하고 있습니다. 산업적 관점에서 이러한 주장은 타당합니다. 현재 우리가 가진 도구는 이것 뿐이기 때문입니다. 더 많이 투자할수록 개발자는 더 깊이 생각하게 되고, 결과적으로 더 나은 결과물을 얻게 되어 회사에 더 큰 이익을 가져다 줄 것입니다.
Huang says engineers not exhausting token limits are "like chip designers using pencils instead of CAD tools." From an industrial perspective, this argument is valid — these are the only tools we have. The more you invest, the deeper developers think, producing better results and greater returns.
그러나 "토큰을 많이 사용할수록 더 많은 가치를 제공한다"는 생각은 경제적 동기 뿐만 아니라 사고와 언어의 관계까지 왜곡합니다.
But the belief that "more tokens equals more value" distorts not just economic incentives, but the very relationship between thought and language.
대부분의 사람들은 단어로 생각하는 경우가 드뭅니다. 대부분의 경우 감각으로 생각합니다.
Most people rarely think in words. Most of the time, they think in sensations.
문제를 풀거나 에세이를 쓰거나 논증을 구상할 때, 뇌는 단어를 만들어내는 대신 끌림 점이라고 밖에 표현할 수 없는 것들을 만들어냅니다. 생각을 따라가다 보면 마치 자신이 생각하는 대상을 둘러싼 개념적 지형이 산과 계곡, 고원, 때로는 늪과 같은 위상 구조를 가진 것처럼, 여기저기로 끌리는 느낌을 받습니다.
When solving problems, writing essays, or constructing arguments, the brain creates what can only be called attractors rather than words. Following a thought feels like being pulled through a conceptual terrain with the topology of mountains, valleys, plateaus, and sometimes swamps.
인간의 마음은 이러한 끌림 점들을 따라 이동하고, 때로는 그곳에서 멀어지기도 하지만, 항상 이러한 "감각"을 매개체로 삼아 나아갑니다.
The human mind moves along these attractors, sometimes away from them, but always navigating through these "sensations" as its medium.
어떠십니까? 약간 복잡하시지요!How does that feel? A bit complex, right?
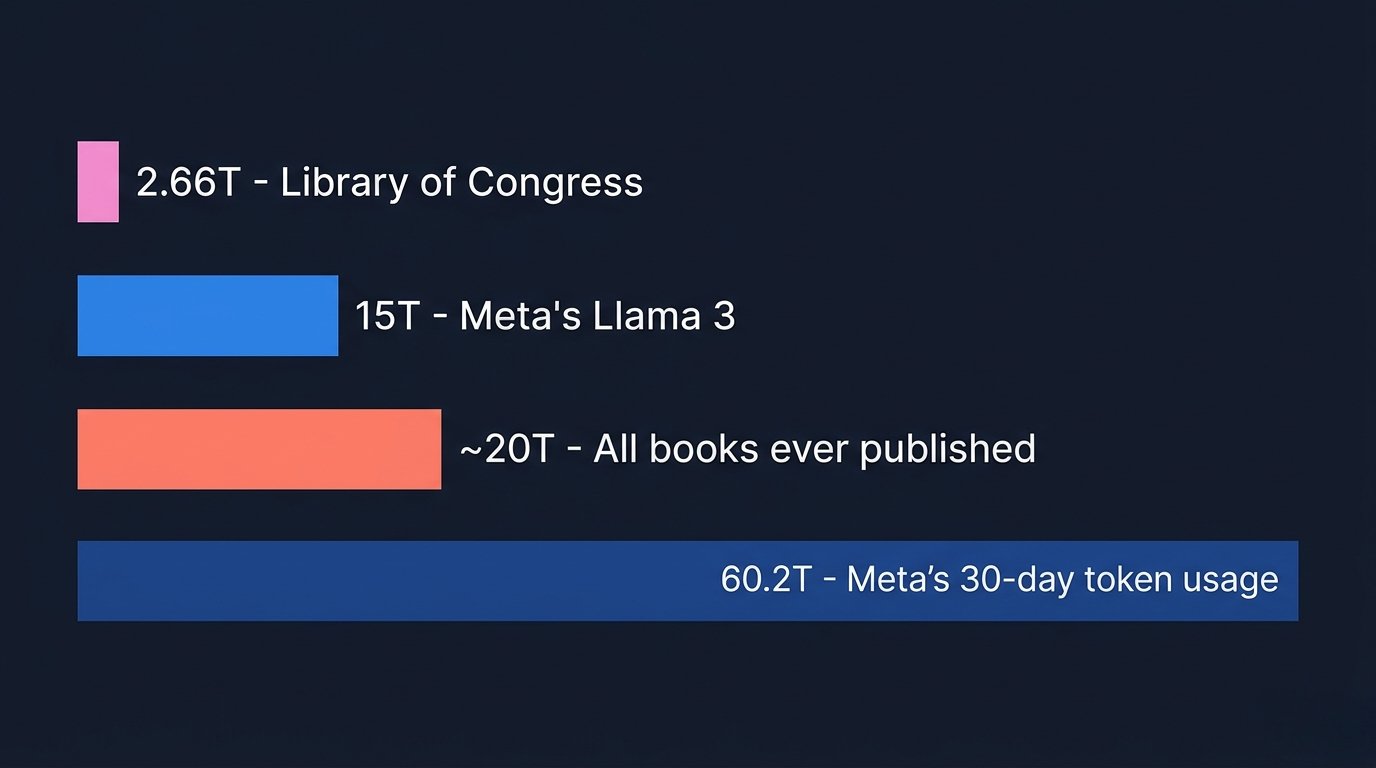
토큰의 우주 — 메타의 30일 토큰 사용량은 역사상 출판된 모든 책의 3배 | 자강헌 제작A Universe of Tokens — Meta's 30-day usage is 3x all books ever published | Jagangheon
한자문화권 VS 영어문화권
Sinosphere vs Anglosphere
먼저 결론부터 말하겠습니다. 우리는 영어문화권과 한자문화권의 인공지능발전 경쟁에서 한자문화권이 승리할 것이라고 주장합니다.
Let us state our conclusion first: we argue that the Sinosphere will prevail over the Anglosphere in AI development competition.
약간 앞으로 돌아가서 인간사고를 거론했는데 인간에게는 사고보다 우선하는 직감이라는 영역이 있습니다. 직감이라고 단순화한 단어를 사용했지만 인간 5감, 즉 청각 시각 후각 촉각 미각이 종합적으로 작용하여 생각과 행동을 결정합니다.
Returning to human thought — there exists a domain called intuition that precedes thinking. We use the simplified word "intuition," but in reality, all five human senses — hearing, sight, smell, touch, taste — work together to determine thought and action.
1945년, 수학자 자크 하다마르는 당대 최고의 과학자들 — 폴리아, 비너, 레비스트로스, 아인슈타인에게 그들이 실제로 어떻게 생각하는지 설문조사를 했습니다. 그들 중 대부분은 말로 대답하지 않았습니다.
In 1945, mathematician Jacques Hadamard surveyed the greatest scientists of his era — Pólya, Wiener, Lévi-Strauss, Einstein — about how they actually think. Most did not answer in words.
아인슈타인의 답변이 가장 유명합니다. "글로 쓰이거나 말로 표현되는 언어의 단어들은 제 사고과정에서 아무런 역할을 하지 않는 것 같습니다." 그는 자신의 사고 요소들이 "시각적이고 일부는 근육적인 유형"이라고 말했습니다. 관습적인 단어들은 "2차 단계에서만 어렵게 찾아내야 하는 것"이라고 했습니다. 그는 1916년 막스 베르트하이머에게도 같은 말을 했습니다. "저는 말로 생각하는 경우가 거의 없습니다. 생각이 떠오르면 나중에 말로 표현해 보려고 할 뿐입니다."
Einstein's answer is the most famous: "Words, as they are written or spoken, do not seem to play any role in my mechanism of thought." He described his thinking elements as "of visual and some of muscular type." Conventional words were "to be sought for laboriously only in a secondary stage." He told Max Wertheimer the same in 1916: "I rarely think in words at all. A thought comes, and I may try to express it in words afterwards."
이 모든 과정은 언어 이전 단계에서, 내가 그것을 말로 표현하는 것보다 훨씬 빠르게 일어납니다. 나중에야 비로소 언어의 구조적 우월성을 이용해 다듬을지 말지를 결정하게 됩니다.
All of this happens at a pre-linguistic stage, far faster than verbal articulation. Only later do we decide whether to refine it using language's structural superiority.
결과를 "내보내기" 위해, 누군가에게 말하기 위해, 기록을 위해, 지도의 세부 사항이 실제 지형과 일치하는지 확인하기 위해 언어가 필요할 수도 있습니다.
You may need language to "export" results, to tell someone, to record, to verify that the map's details match the actual terrain.
그러려면 단어가 필요합니다. 하지만 단어는 더 풍부한 무언가를 압축하는 손실이 있는 표현입니다. 더 구체적이지만 덜 정확하고, 더 쉽게 전달되지만 덜 정밀합니다.
For that, you need words. But words are lossy compression of something far richer. More specific but less accurate, more easily transmitted but less precise.
한 장의 그림이 천 마디 말보다 낫다는 말이 있듯이, 감각적인 생각은 대하소설보다 가치가 있을 수 있습니다.
Just as one image can surpass a thousand words, sensory thought can be worth more than an epic novel.
한자는 기본적으로 표의문자에 속하나, 문자가 만들어지고 사용되는 방법에 따라서 더 자세하게 나눌 수 있습니다. 상형(象形), 지사(指事), 회의(會意), 형성(形聲), 전주(轉注), 가차(假借)의 여섯 가지를 육서라고 합니다. 한자에서 각 분류가 차지하는 비중은 상형과 지사가 가장 낮고, 형성이 가장 높습니다. 상형, 지사, 회의, 형성 네 가지는 글자를 만드는(造字) 방법이고, 전주, 가차는 글자를 활용하는(運用) 방법입니다. 다만, 전주는 조자인지 운용인지에 대해서 논란이 약간 있습니다. 이는 전주 자체의 모호성 때문입니다.
Chinese characters fundamentally belong to ideographic writing, but can be further classified by how they are created and used. The six categories are called the Six Principles (六書): pictographic (象形), indicative (指事), associative (會意), phono-semantic (形聲), derivative (轉注), and phonetic loan (假借). Among these, pictographic and indicative have the lowest proportion while phono-semantic is the highest. The first four are methods of creating characters (造字), while the last two are methods of utilizing them (運用). However, there is some debate about whether derivative belongs to creation or utilization, due to the inherent ambiguity of the category itself.
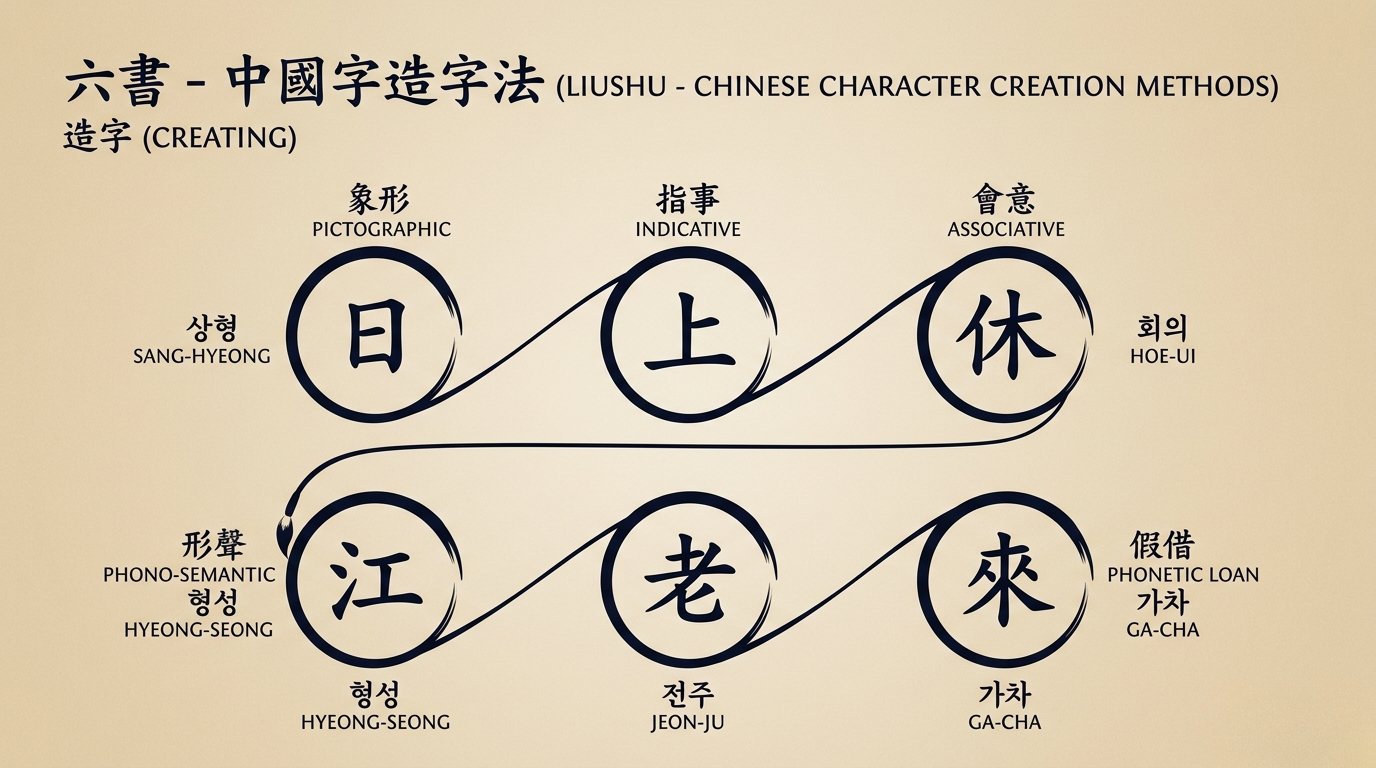
六書 — 한자의 여섯 가지 조자·운용 원리 | 자강헌 제작六書 Liushu — Six principles of Chinese character creation and usage | Jagangheon
이 만큼만 설명해도 한자는 표음문자인 영어가 도저히 따라갈 수 없는 복합성을 확보하고 있습니다. 때문에 민족을 강조하지 않더라도 세계 도처에 차이나타운이 있고 세계에서 가장 거대한 인구단위의 결속력이 높습니다.
Even this much explanation demonstrates that Chinese characters possess a complexity that English, as a phonetic alphabet, simply cannot match. This is why, without emphasizing ethnicity, Chinatowns exist worldwide and the largest population bloc in the world maintains such strong cohesion.
토큰규모에 매몰
Trapped in Token Scale
영어문화권은 토큰규모에 매몰된 인공지능생태계를 향해 달려왔습니다. GPU의 Nvidia, 거대 데이터 센터, 압도적 전력량, 이 모든 현상이 토큰규모에 매몰된 현실을 웅변하고 있습니다.
The Anglosphere has been racing toward an AI ecosystem trapped in token scale. Nvidia's GPUs, massive data centers, overwhelming power consumption — all these phenomena testify to a reality trapped in token scale.
메타 직원들은 클로데오노믹스(Claudeonomics)라는 내부 순위표를 가지고 있습니다. 순위는 일반 사용자부터 "세션 불멸자(Session Immortal)"를 거쳐 최상위 등급인 "토큰 전설(Token Legend)"까지 올라갑니다. 결과로 메타가 30일 동안 대시보드에서 사용된 총 토큰(단어 수)이 약 60조 개를 넘어섰다는 사실은 정말 놀랍습니다. 참고로, 역사상 출판된 모든 책의 총 토큰 수를 계산하면 약 20조 개가 될 것으로 추정됩니다.
Meta employees have an internal leaderboard called Claudeonomics. Ranks climb from regular users through "Session Immortal" to the top tier: "Token Legend." The result — Meta's dashboard showed over 60 trillion total tokens used in 30 days. For reference, every book ever published in history is estimated at roughly 20 trillion tokens.
이는 메타가 지난달에 클로드의 추론과정을 분석하여 이번 새 버전을 출시하는 데 필요한 데이터를 추출하기 위해 클로드 모델에 60조 토큰을 썼다는 말인가요? 만약 그게 사실이라면, 정말 심각한 일이네요.
Does this mean Meta spent 60 trillion tokens on Claude models last month to analyze its reasoning process and extract data for their new version? If true, this is truly serious.
메타가 이런 행위를 했을 가능성은 다음과 같습니다. 메타는 (중국 연구소에서 나온 가짜 계정들과 달리) 실제 계정을 여러 개 생성한 다음, 이 계정들을 이용해 더욱 강력한 모델(클로드)에 추론 패턴을 추출하도록 정교하게 설계된 프롬프트를 집중적으로 입력합니다. 그런 다음 출력 값을 수집합니다. 그리고 이 출력 값을 자체 모델의 학습 데이터로 사용합니다. "학생"은 "선생님"의 행동을 처음부터 스스로 연구할 필요 없이 모방하는 법을 배우게 됩니다. 이는 자체적으로 기능을 개발하는 것보다 훨씬 저렴하고 빠릅니다.
How Meta might have done this: unlike fake accounts from Chinese labs, Meta creates multiple real accounts and uses them to feed carefully designed prompts to a stronger model (Claude), extracting reasoning patterns. It then collects the outputs and uses them as training data for its own model. The "student" learns to mimic the "teacher" without having to develop capabilities from scratch — far cheaper and faster.
그러면 메타가 불법적인 일을 했다고 비난하는 건가요? 저희는 그렇게 생각하지 않습니다. 토큰규모에 매몰된 현실을 직시하자는 주장입니다. Anthropic의 이용 약관은 경쟁 모델 학습에 결과물을 사용하는 것을 금지하지만, 대규모 합법적 고객인 Meta에 대한 단속은 중국의 프록시 네트워크를 적발하는 것과는 완전히 다른 문제입니다.
Are we accusing Meta of doing something illegal? We don't think so. Our argument is to face the reality of being trapped in token scale. Anthropic's terms of service prohibit using outputs to train competing models, but policing a massive legitimate customer like Meta is an entirely different problem from catching Chinese proxy networks.
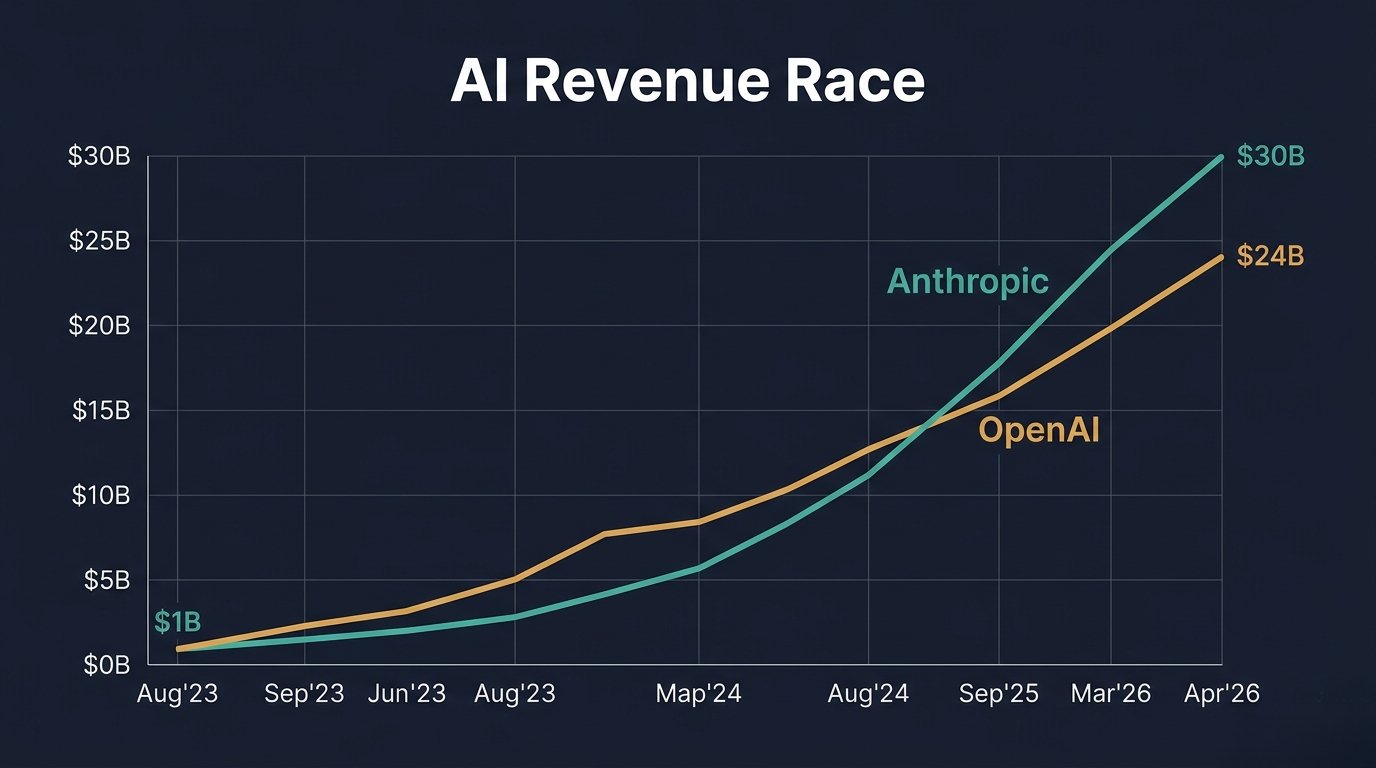
AI Revenue Race — Anthropic이 OpenAI를 추월하다 | 자강헌 제작AI Revenue Race — Anthropic surpasses OpenAI | Jagangheon
제시한 도표를 보면 무엇인가 느낌이 오지 않습니까?Looking at this chart, doesn't something click?
Anthropic과 OpenAI — OpenAI는 시장지향적 DNA가 있다면, Anthropic(인류)은 처음부터 인간에 집중해 왔습니다. 때문에 규모에서, 시작시점에서 OpenAI에 열세이고 최근 미국 국방부와 충돌이라는 악재에도 높은 성과를 달성하고 있습니다.
Anthropic vs OpenAI — if OpenAI has market-oriented DNA, Anthropic ("humanity") has focused on humans from the start. Despite being smaller, starting later, and recent friction with the U.S. Department of Defense, it has achieved remarkable results.
물론 OpenAI와 Anthropic의 회계기준이 동일하지 않습니다. 그러나 Anthropic의 성장 추세는 누구도 부인하지 못합니다.
Of course, OpenAI and Anthropic don't share the same accounting standards. But no one can deny Anthropic's growth trajectory.
결론
Conclusion
이 주제의 최종 결론에 왔습니다. 자강헌은 그간 언어에 국한되지 않는 인간의 5감을 깨울 수 있는 인포그래픽 등 다양한 정보와 자료를 수집해 왔고, 그를 통해 스스로를 강하게 하는 공부방을 형성했습니다.
We have reached the final conclusion. Jagangheon has been collecting diverse information through infographics and various materials that can awaken the human five senses beyond language alone, and through this has formed a study space where everyone grows stronger on their own.
한번쯤 방문해 보시지 않겠습니까?Would you like to visit?